MaRS: A Multi-Modality Very-High-Resolution Remote Sensing Foundation Model with Cross-Granularity Meta-Modality Learning
Abstract
We propose MaRS, a multi-modality very-high-resolution (VHR) remote sensing foundation model designed for cross-modality, cross-granularity interpretation of complex scenes. We construct MaRS-16M, a large-scale VHR SAR optical paired dataset (16M+ pairs) via collection and semi-automated processing. MaRS tackles two core VHR SAR optical SSL challenges: imaging discrepancy and modal representation gap. To this end, we introduce Cross-Granularity Contrastive Learning (CGCL) to alleviate alignment inconsistencies by linking patch- and image-level semantics, and design Meta-Modality Attention (MMA) to unify heterogeneous physical characteristics across modalities. Compared with existing RSFMs and general VFMs, MaRS serves as a strong pretrained backbone across nine multi-modality VHR downstream tasks. Dataset and code are available at the project page.
Highlights & Contributions
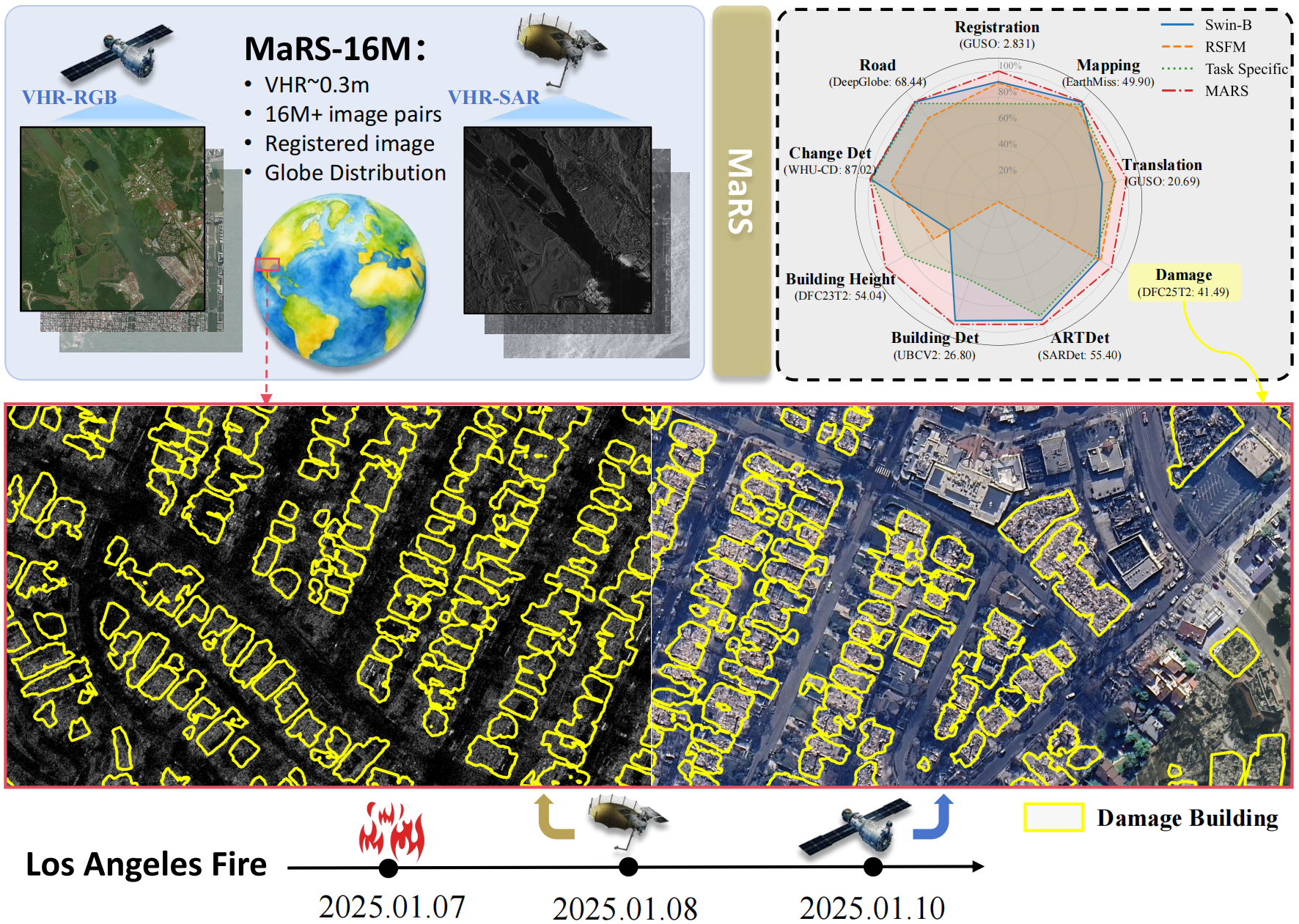
- MaRS-16M: a globally distributed, precisely paired VHR SAR optical dataset with 16,785,168 patch pairs (0.35 m GSD).
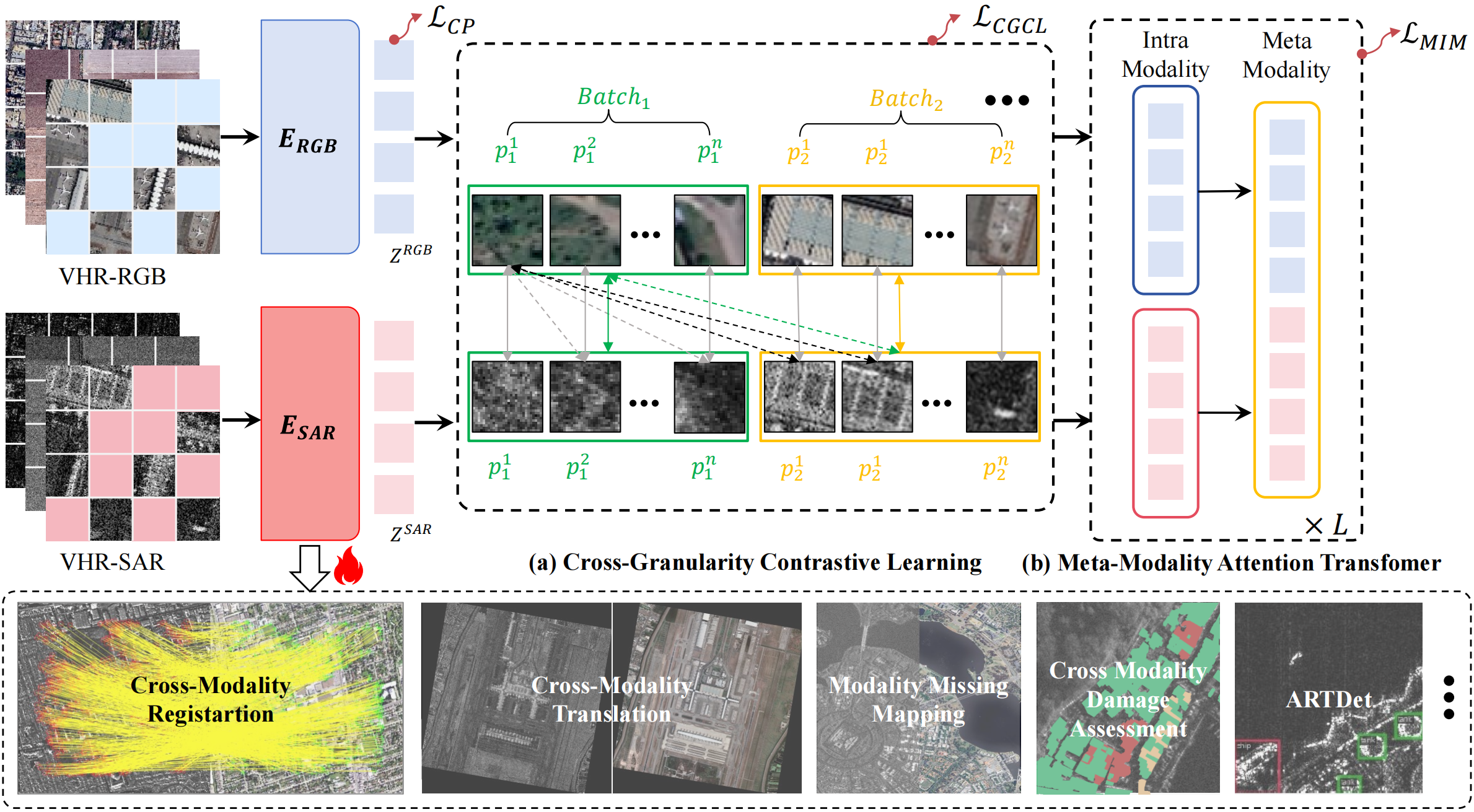
- MaRS model: dual-encoder (SwinV2) with CGCL (patch/global & patch-to-global alignment) and MMA (alternating intra-/cross-modality attention) for robust fusion.
- State-of-the-art results on nine VHR multi-modal tasks (registration, translation, mapping under modality-missing, change/damage, detection, height estimation, roads, etc.).
Capabilities
- Handles VHR SAR & optical with robust cross-modal alignment and fusion.
- Generalizes to fine-grained urban/disaster scenarios and low-visibility conditions.
- Serves as a pretrained backbone across diverse downstream tasks with strong transfer.
Method Overview
Architecture. MaRS adopts dual encoders (ERGB, ESAR, both SwinV2) to extract modality-specific tokens, followed by a Meta-Modality Attention (MMA) Transformer that alternates intra-modality and cross-modality attention to form a unified representation. Light decoders are used for dense prediction.
Pretraining. We combine three self-supervised strategies: (1) CGCL at patch-, image-, and patch-to-global levels to mitigate local distortions while preserving global semantics; (2) masked image modeling per modality branch; (3) continued pretraining on VHR optical to further strengthen representation quality. Training uses 512├Ś512 inputs, 60% masking, and runs on 8├ŚA800 GPUs.
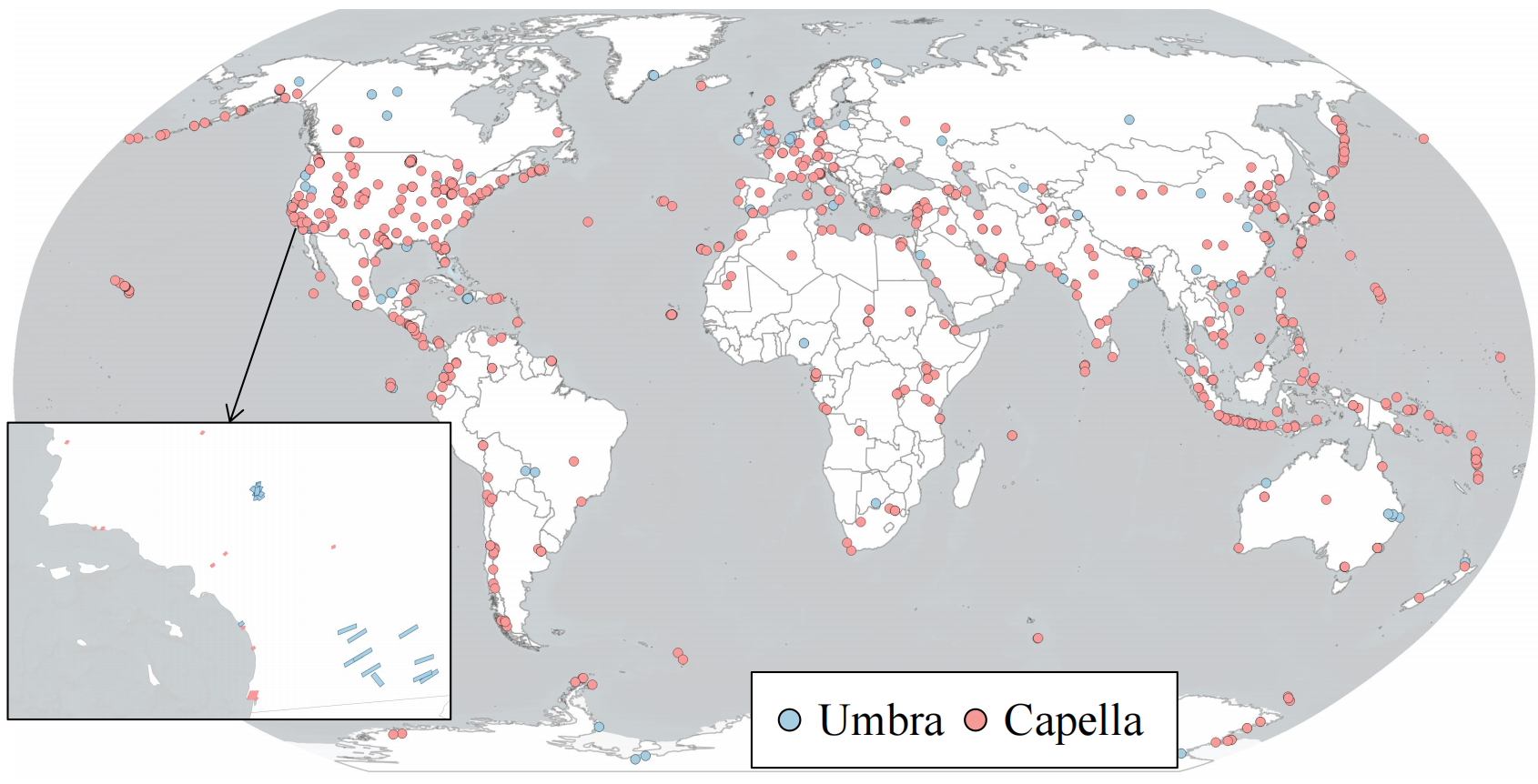
Dataset Distribution
Key Parameters
- Pairs: 16,785,168 SAR optical patch pairs (Ōēł0.35 m GSD).
- SAR Sources: Umbra & Capella; X-band; HH or VV polarization.
- Collection: 4,225 VHR SAR images collected (to 2024-12-30), quality-filtered; corresponding VHR optical retrieved.
- Preprocess: registration checker ŌåÆ resampling ŌåÆ registration; standardized 512├Ś512 patches for training/eval.
- Coverage: diverse land cover, urban patterns, disaster scenarios; globally distributed.
- Use: designed for large-scale SSL and robust cross-modal alignment under geometric distortion/noise.
Experiments & Results (VHR Multi-Modal)
MaRS is evaluated across nine representative VHR tasks and achieves strong results compared with RSFMs/VFMs and task-specific methods:
- Cross-Modality Registration (GUSO): RMSE Ōēł 2.83.
- Modality-Missing Mapping (EarthMiss): mIoU Ōēł 49.90.
- Cross-Modality Translation (GUSO): PSNR Ōēł 20.69, SSIM Ōåæ.
- SAR Target Detection (ARTDet) / SARDet-100K: mAP Ōēł 55.40.
- Building Detection (UBC-V2): mAP Ōēł 26.80.
- Building Height Estimation (DFC23-T2): ╬ö (height) Ōēł 54.04.
- Change Detection (WHU-CD, optical): IoU Ōēł 87.02.
- Road Extraction (DeepGlobe, optical): IoU Ōēł 68.44.
- Damage Assessment (DFC25-T2): IoU Ōēł 41.49.

Feature Activations
MaRS produces sharper activations along object boundaries and shows more consistent activation regions across RGB/SAR, indicating improved modality-invariant representation and fine-grained detail modeling.

BibTeX
@inproceedings{Yang2026MaRS,
title={MaRS: A Multi-modality Very-high-resolution Remote Sensing Foundation Model with Cross-Granularity Meta-Modality Learning},
author={Yang, Ruoyu and Liu, Yinhe and Yan, Heng and Zhou, Yiheng and Fu, Yihan and Luo, Han and Zhong, Yanfei},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={40},
number={14},
pages={11685--11693},
year={2026},
doi={10.1609/aaai.v40i14.38153}
}